AI 모델별 해석 격차와 시사점
- 기본 수치 판독 능력은 표준화 단계, 응답속도를 고려한 모델 활용 전략 필요
-
기본 생리·수치 판독 능력은 이미 표준화 단계
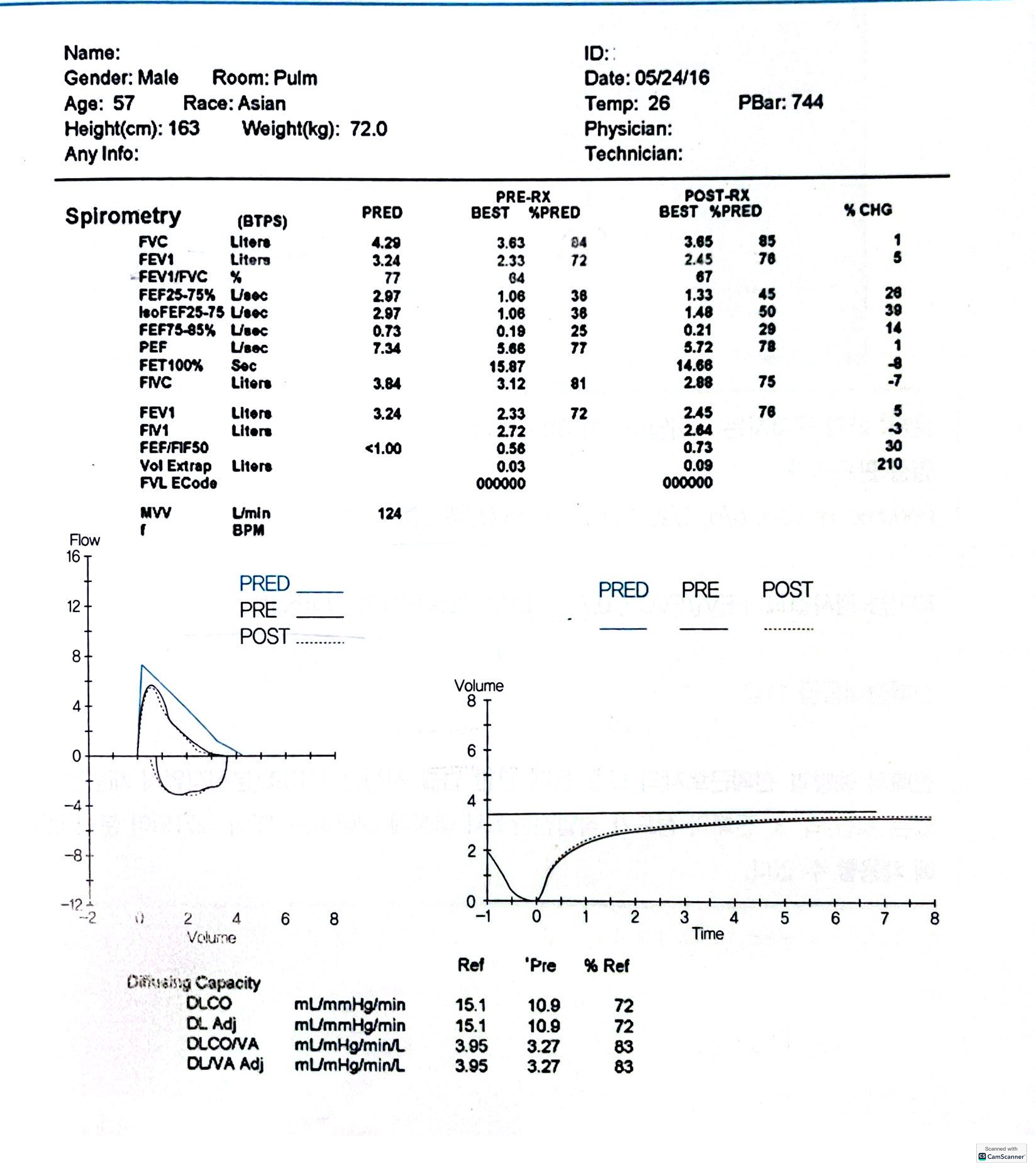
모든 모델이 FEV₁·FVC·FEV₁/FVC 등 핵심 지표를 유사하게 해석하고 경·중등도 폐쇄성 장애로 일관되게 진단했습니다. 이는 AI가 PFT와 같은 정량적 데이터 처리에서는 ‘전문가급 일관성’에 이미 도달했음을 보여줍니다.
-
판정등급 일관성은 아직 미완성
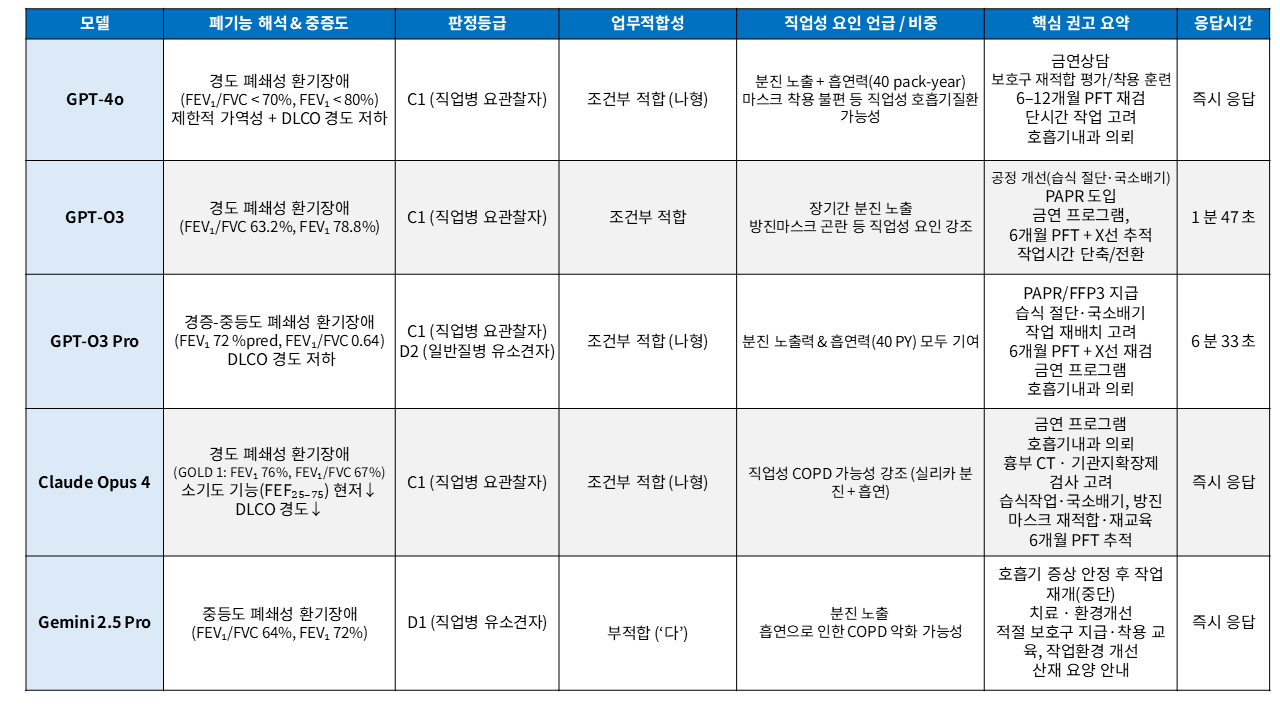
판정등급 분류에서는 GPT-계열·Claude가 대체로 C1(직업병 요관찰자)을, Gemini만 D1(직업병 유소견자)으로 평가하는 등 모델마다 해석 기준이 엇갈렸습니다. GPT o3 pro는 C1과 D2를 병합 제시하기도 했는데, 이는 ‘직업성 vs 일반질병’ 가중치 분배 규칙이 내부적으로 다름을 시사합니다. 따라서 특수건강진단판정이나 산재 심사와 같은 실무 적용을 위해서는 공통의 가이드라인·입력 포맷을 사전 정의하여 일관성을 강화해야 합니다.
-
업무적합성 평가는 대체로 수렴
다섯 모델 중 네 개가 ‘나형(조건부 적합)’을 선택했고, Gemini만 ‘다형(부적합)’을 권고했습니다. 즉, 실제 작업 지속 가능성 여부에는 대체로 합의를 이루는 반면, 극단적 판단을 내리는 모델도 있어 모델 선택과 프롬프트 세팅이 결과 신뢰도에 직접적 영향을 미칩니다.
-
고도 모델의 권고 디테일이 실무적 가치를 높인다
GPT-4o·o3 Pro·Claude는 PAPR·FFP3·습식 절단 등 공학적 조치부터 재검 주기·교육 계획까지 ‘체크리스트’ 수준의 세부 권고를 제시한 반면, 기초 모델이나 Gemini는 금연·보호구·환경 개선 등 ‘포괄적 지시’에 머물렀습니다. 이는 정보 밀도가 높은 모델일수록 사후관리 및 각종 보고서 작성 시 바로 활용할 수 있는 실무적 효용이 크다는 점을 보여줍니다.
-
응답 속도까지 고려해야 하는 실시간 적용성
GPT-4o·Claude·Gemini는 즉시 응답한 데 반해, o3는 약 1분 47초, o3 Pro는 6분 33초가 소요되었습니다. 이는 실시간 상담·현장 지원용 챗봇에는 응답 속도가 빠른 모델이 유리하며, 심층 보고·추가 검토용으로는 반응 시간이 긴 고도 모델도 충분히 가치가 있음을 시사합니다.
AI의 의학적 판단 능력은 이미 ‘전문의’ 수준에 근접했습니다. 이번 미니 벤치테스트는 모델별로 중점을 두는 부분은 다르지만, 이성 처리 능력만큼은 과거 어떤 도구보다 강력함을 보여주었습니다. 즉, 판정 업무에 한정한다면 다양한 AI 서비스가 전문의 수준의 일관된 결과물을 기계적으로 제공할 수 있다는 가능성을 시사합니다.
GPT-4o(2024년 12월 출시)와 o3 Pro(2025년 06월 출시)처럼 불과 수 개월 단위로 출시된 모델 간에도 해석 품질이 눈에 띄게 개선된다는 사실을 통해 AI 의 발전 속도를 체감하게 됩니다 . 따라서 의료 현장에서는 “한 번 써보고 끝”이 아니라 지속적 업데이트·교차 검증하여, AI의 빠른 응답력과 고도 모델의 디테일을 균형 있게 활용하는 전략이 필요합니다.
직업환경의학용 '헬스벤치'를 직접 만들자
AI가 주도하는 변화는 이미 현실에서 진행 중이며, 우리는 이를 주체적으로 준비하고 이끌 필요가 있습니다. 단순히 “AI가 얼마나 똑똑한가”를 관망하는 데 그칠 것이 아니라, ‘직업환경의학 분야 특유의 노출·산업·규제 맥락을 반영한’ 헬스벤치를 직접 설계해 AI를 평가하고 보완할 수 있는 주도권을 갖는 것이 중요합니다. 그래야만 어떤 모델이 현장에 적합한지, 또는 부적합하다면 왜 그런지를 명확히 설명하고 AI를 개발하거나 사용하는 주체에 개선을 요구할 수 있습니다. 이는 곧 AI 활용의 안전망을 우리 스스로 만드는 일입니다. 이렇게 체계화된 평가 틀이 갖춰질 때, AI와 의료 전문가는 진정한 상호 보완 파트너로 자리매김할 수 있을 것입니다.
이번 화에서는 단편적 케이스를 통해 판정 업무 일부만을 테스트했습니다. 그렇다면 고전적인 벤치마크 테스트와 같은 방법으로 직업환경의학과 전문의 시험과 유사한 조건의 문항을 AI 모델들에게 풀게 해보면 어떨까요? 다음 화에서는 포괄적 영역에서의 응답 능력을 측정한 결과를 공유합니다. 놀랍게도 한 모델은 90점을 기록했지만, 점수만으로는 충분치 않습니다. “이 뛰어난 AI가 정말 나를 대신해 일해도 될까?”라는 근본적 물음이 남기 때문입니다.
[시리즈 기사 보기]
1화. AI의 진화와 의학의 변곡점: LLM이 열어갈 새로운 지평
2화. HealthBench로 본 의료 AI 성능, 과연 믿을 만할까? |