AI모델이 믿을만한지 평가하는 방법 - 의사면허시험 통과하기
의료 분야에서 인공지능의 활용 가능성을 논할 때, 가장 중요한 전제는 ‘이 모델이 정말 믿을 만 한가?’라는 질문에 통과해야 한다는 것입니다. 초기 의료 AI 의 벤치마크 테스트는 인간 의사가 치르는 면허시험을 그대로 활용하는 방식으로 시작되었습니다. USMLE(미국 의사면허시험)나 KMLE(한국 의사국가고시) 같은 표준화된 시험을 통해 모델의 성능을 측정하고 비교하는 것이 주된 방법이었습니다.
하지만 이러한 접근법은 실제 의료 상황에서도 시험점수와 동등한 성능을 보장해주지 못한다는 한계를 드러냈습니다. 객관식 문제는 실제 임상의 다층적 복잡성을 포착하지 못했고, 단답형 질문 역시 환자와의 역동적 상호작용이나 불완전한 정보 속에서 추가 단서를 찾아내는 능력을 평가할 수 없었습니다.
무엇보다 AI 기술의 급속한 발전으로 대부분의 최신 모델이 정답률 90%를 상회하는 점수를 기록하면서, 이들 시험은 변별력을 상실하고 성능 비교의 도구로서 효용성을 잃게 되었습니다.
*벤치마크 테스트란
어떤 기술이나 도구의 성능을 객관적으로 비교·평가하기 위해 만들어진 표준화된 시험 환경이나 기준을 말합니다. 예를 들어 AI의 의료 분야 활용 가능성을 평가할 때, 동일한 질문이나 상황을 여러 모델에 제시해 그 응답의 정확도나 일관성을 비교하는 방식이 대표적입니다.
AI 신뢰성을 평가하는 새로운 패러다임의 등장, 대화형 임상 벤치마크
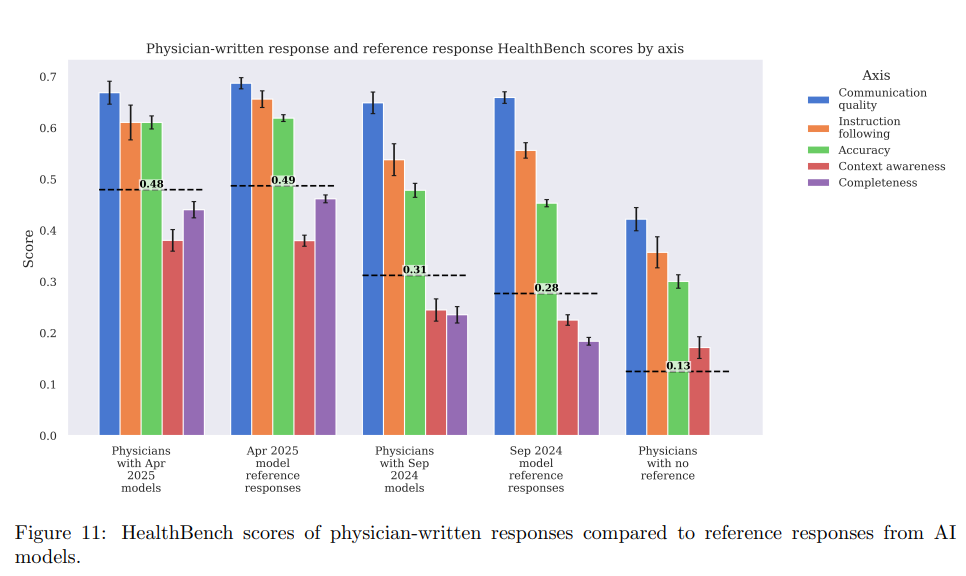
이러한 상황에서 의료 AI 모델 검증의 새로운 패러다임은 OpenAI가 열었습니다. 2025년 5월에 공개한 HealthBench는 대형언어모델(LLM)이 실제 의료 상황에서 얼마나 잘 대응하는지를 평가하기 위해 개발되었습니다. 기존의 객관식 시험 방식과는 달리, 262명의 의사가 직접 만든 5,000개의 실제 대화 시나리오를 통해 AI가 환자나 의료진과 대화할 때 얼마나 적절하게 반응하는지를 살펴보는 방식을 취합니다. 응급 상황 판단, 자원이 부족한 환경에서의 조언, 불확실한 상황 대처 등 7가지 주제로 나뉘어 있고, 각 답변은 정확성, 완성도, 상황 인식, 소통 품질, 지시 따르기 등 5가지 측면에서 평가받습니다. 쉽게 말해, "정답을 맞추는가?"보다는 "실제로 환자나 의사와 대화할 때 얼마나 도움이 되는가?"를 측정하려는 의도인 것입니다.
[논문 보기] / [GitHub 자료]
💻직접 실행해 보고 싶다면?
- git clone <https://github.com/openai/simple-evals.git> 후 폴더 진입
- pip install -e evals/ 로 의존 패키지 설치
- export OPENAI_API_KEY=본인키 입력
- python healthbench_eval.py --model gpt-4o --num_conversations 50 실행만 하면 샘플 50개 대화로 바로 점수를 확인하실 수 있습니다. 필요하면 JSON 시나리오와 루브릭 파일을 바꿔 직업환경의학 전용 ‘미니 헬스벤치’도 손쉽게 만들어 볼 수 있습니다.
대화형 임상벤치마크 시험 결과
- 의사와 AI 가 협업했을 때 가장 좋은 결과
Healthbench 를 눈여겨 봐야 하는 이유는 다음과 같습니다.
첫째, 4만 8천개가 넘는 평가 기준을 의사들이 직접 만들어서, AI의 의료 대응 능력을 평가하는 믿을 만한 기준을 처음으로 마련했다는 점(전 세계 60개국 262명의 의사가 참여), 둘째, OpenAI가 모든 평가 도구와 데이터를 공개해서, 앞으로 나올 의료 AI들이 같은 기준으로 공정하게 평가받을 수 있는 환경을 만든 점, 마지막으로, 최신 AI 모델들은 여러 항목에서 일반 의사들의 평균 점수를 넘어섰고, 특히 의사가 AI의 도움을 받았을 때 가장 좋은 성과를 냈다는 점입니다.(아래의 그래프) 결국 이 결과는 “AI와 의료 전문가가 상호 보완적으로 협력할 가능성”을 시사합니다. |